Compact translation models
Introduction
Energy consumption of machine translation
Modern machine translation relies on a specific type of neural network, called transformer. Training a transformer model usually consumes significant amounts of energy: in Strubell et al. (2019), the energy consumption for training a normal-sized transformer-base model was estimated as 27 kWh, and training a larger transformer-big model as 201 kWh. While the amount of energy required to train a single transformer model is not huge, machine translation development usually involves training and testing many variants of models, which multiplies the energy consumption of training. Generating translations with transformer models also requires energy. As with training, bigger models require more energy to generate translations than smaller models.
Reducing model size
The best way to reduce the energy consumption of transformer models is to reduce their size, since smaller models use less energy when being trained and when generating translations. However, size reduction is only useful, if the quality of the translations that the smaller model produces remains competitive.
In the GreenNLP project, we will explore different methods which reduce translation model size without compromising quality. The most common way of creating machine translation models that are small but perform well, is to use knowledge distillation, which means compacting the knowledge embedded in a large model into a smaller model (you can see the effect of knowledge distillation on model sizes in the table below). In addition to knowledge distillation, we will explore retrieval-augmented translation models, which utilize external information sources in generating translations.
| Model type | Model size | Time to translate 48,000 words |
|---|---|---|
| big | 891 MB | |
| base | 294 MB | 46.36s |
| small | 226 MB | 24.07s |
| tiny11 | 96 MB | 10.98s |
| tiny | 89 MB | 6.22 |
Table 1. The effect of knowledge distillation on model size and translation speed (Tiedemann et al., 2023)
Machine translation training pipeline
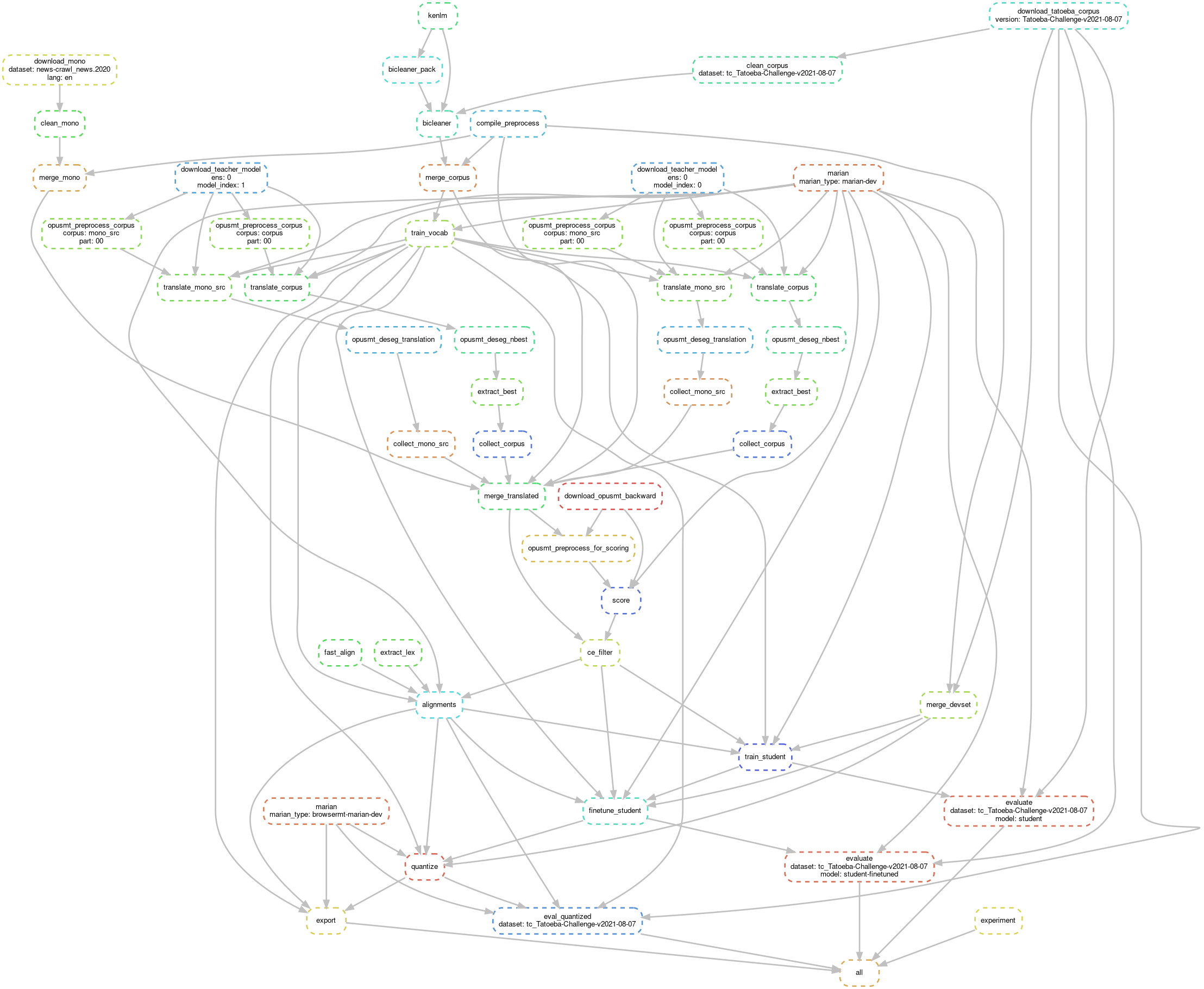
firefox-translations-training pipeline
Reducing the energy consumption of machine translation models first of all requires that there is a system in place for consistently tracking the energy consumption of MT training and generation. GreenNLP project uses a modified version of the firefox-translations-pipeline, originally developed as part of the Bergamot project, to record detailed information about the energy consumption data during different training steps.
firefox-translations-pipeline also includes out-of-the-box support for knowledge distillation, which is used as a foundation for knowledge distillation experiments within the GreenNLP project. An important addition to the pipeline is the possibility to use machine translation models trained in the OPUS-MT and Tatoeba-Challenge project as sources of knowledge for knowledge distillation.
Example of a pipeline job
The training pipeline can run jobs with different configurations. Below is a diagram of one possible job configuration, where pretrained OPUS-MT models are used (click to zoom).